
機械学習は最近よく聞く単語です。AIとも呼ばれるようになり,より一層ブラックボックス化しています。そこでこの記事では少しだけブラックボックスの中を覗き,「ちょっと興味あるけど例えばどうやって,何を使って,何に使えたりするの?」という人向けに簡単に解説します。
目次
機械学習とは
経験則を瞬時に出せる”勘”
簡単に言ってしまえば,経験則を瞬時に出せるようになるのが機械学習です。例えばexcelでこのようなデータがあったとします。”1″は購入,”0″は購入していないことを示しています。
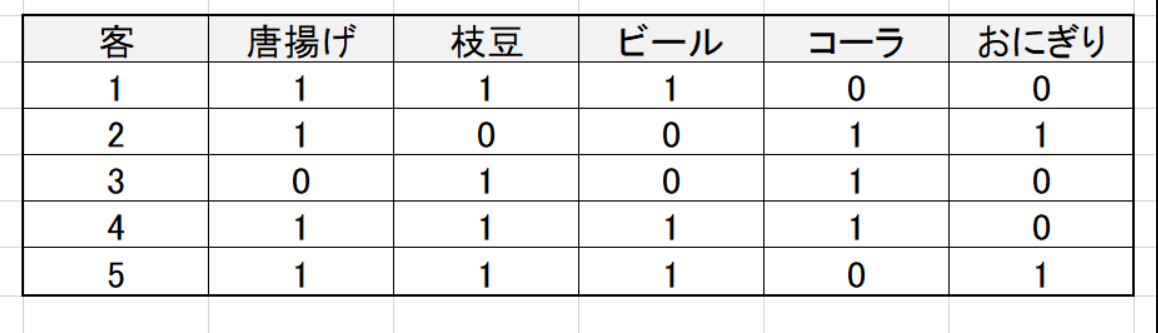
このデータを人間が見るに,「唐揚げと枝豆を買った人はビールも買う傾向にあるな」というのが分かると思います。これで,新しいお客さんが来ても「その人が唐揚げと枝豆を買ったか」を聞けば,同時にビールも買っているかが高確率で予測できますね。 今この瞬間,あなたは機械学習と同じことをしました。
この予測に使った材料の「唐揚げ,枝豆を買ったかどうか」を特徴量と呼んでいます。特徴量から答えがどうなるかを考えるわけです。
このプロセスには便利な日本語が昔からあります。それは勘です。今までの経験を糧にして未来を予測しているわけですから,機械学習の精度が上がれば勘で生きている人間にとって代わることも可能です。AIと呼ばれるのも当然かもしれませんね。
機械学習には大きく分けて2種類あります。それは回帰とクラス分類です。
回帰
回帰とは,「特徴量の傾向から,新しい特徴量の値を算出する」ものです。下のようなデータがあったとします。
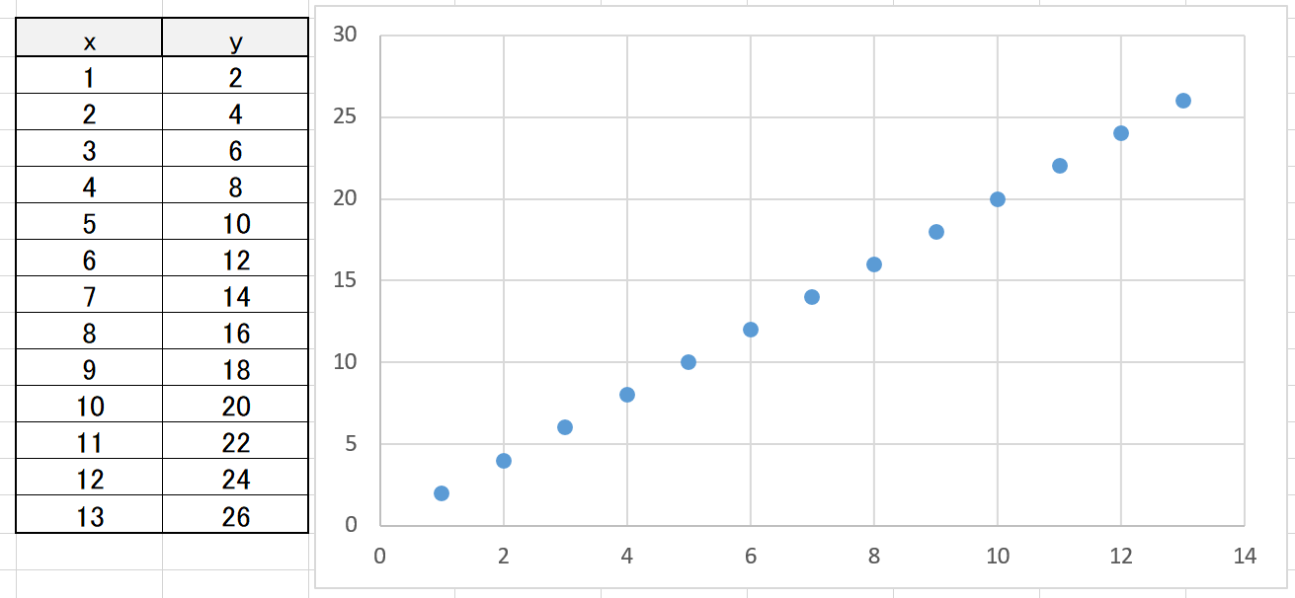
瞬時に分かると思いますが,これは
y = 2x
です。この時にxとyの関係を予測し,未知のxの値を算出するのが回帰となります。「xが2.5の時」は?もちろん5ですね。その予測行為が回帰です。
クラス分類
クラス分類とは,「特徴量からどのクラスになるかを予測する」ものです。例えば上のビールの例はまさにクラス分類で,特徴量から①ビールを買う人 と ②ビールを買わない人 にクラスを分類しています。この対象となるクラスは2つ以上ももちろん可能です。
代表的な機械学習アルゴリズム
k-最近傍法
最も単純だと言われているアルゴリズム。特徴量が最も近いデータのクラスを予測結果とする。例えば先程の客のデータにおいて,客1~4までを学習済みだとしましょう。新しいデータとしてビール購入情報を持たない客5を入れると,客1に最も近い特徴量を持っているのでビールを買うと予想されます。
ランダムフォレスト
これは特徴量ごとにyes/noを決めてふるい分けるアルゴリズムです。一つずつ特徴量を聞いていき,最後にそのyes/noのふるい分けからクラスを決定します。人の特徴からその人を予想して出してくるアキネーターと全く同じです。このアルゴリズムに大量のデータx1,x2,x3,,,xnとそのクラスyを与えてあげれば,勝手にその分岐を作ってくれます。この分岐がまるで木の枝のようであることからランダムフォレストと呼ばれています。
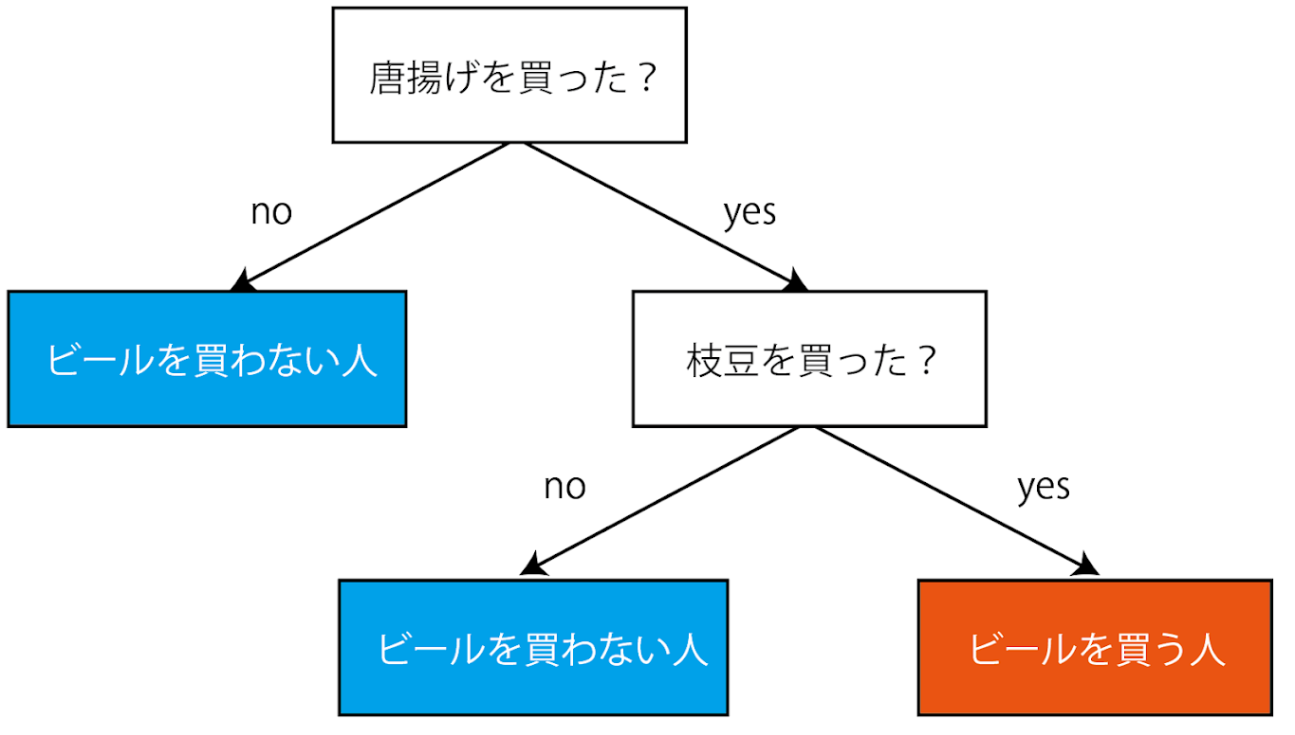
先程の例だとこうなります。枝の先端にはクラスが位置します。これはyes/noになればいいので,例えばx>20ならクラス1,そうでないならクラス2など,数の比較で分類していくことができます。
ニューラルネットワーク
これは最近のAIブームのきっかけとなったアルゴリズムです。人間の脳にある「ニューロンと呼ばれる演算細胞」のネットワークを模して造られています。特徴として,特徴量から新しい特徴量を作り,それからまた新しい特徴量を作り…というのがあります。
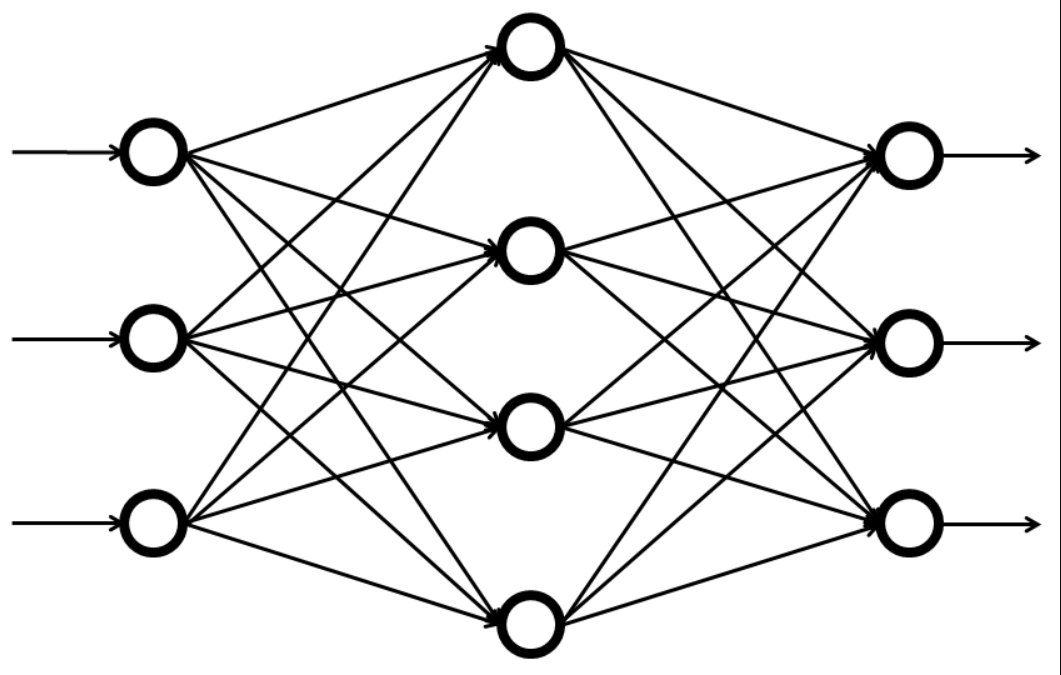
これはパーセプトロンと呼ばれるもので,層状に特徴量が作られています。特に画像からの顔認識などは「ピクセル1が何色で…」とするよりも輪郭を捉える方が重要です。そのような時に多層構造にしていくつかの特徴量を掛け合わせたものを使えば予測がしやすいことが分かってきました。そのため,自動運転や物体の認識には欠かせないアルゴリズムです。
それではここから実践としてpythonを使って予測してみましょう。簡単すぎて驚くこと間違いなしです。
pythonの便利ライブラリ「scikit-learn」
なぜpythonなのか
pythonはプログラミング言語の一種で,近年人気のある言語です。これまでのjavaやC++,C#等はCUIアプリケーション,GUIアプリケーションを作るのに非常に便利でした。ですがコードを書いてコンパイルする必要があり,すぐに実験をするような使い方は難しいです。
pythonはこれらとは違い,インタープリター言語です。コードを打ち込むことで,すぐにその行だけ実行されるので対話的に作業することができます。
また,pythonにはNumpyやpandasなど,数学的・統計的な処理がしやすいライブラリがある他,機械学習がかなり簡単に実装できるscikit-learnというライブラリがあります。これが今回pythonを使う大きな理由です。
anacondaのインストール
anacondaとはpythonで機械学習を始めるのに必要なライブラリがセットになったソフトだと考えてください。こちらのサイトを参考にインストールしましょう。
実際に予想してみよう
jupyter notebookを起動する
jupyter notebookとは,簡単にpythonコードが実行,実験できるソフトです。
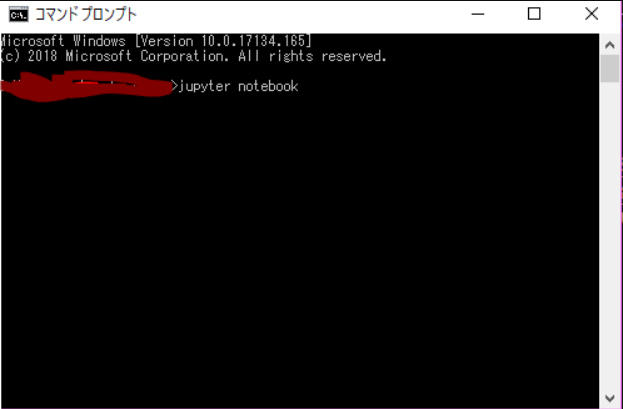
まずコマンドプロンプトを開いて,
jupyter notebook
と入力してEnterを押しましょう。暫くするとブラウザが開き,起動します。

次に右側にあるNewからPython 3を選びます。これで新しい編集画面が開いたはずです。
scikit-learnを読みこむ
一つ目の入力欄に下のように入力し,shift+Enterをしてください。すると初めの入力欄(セルという)が実行され,次のセルが現れます。
import numpy as np
import sklearn
from sklearn.neighbors import KNeighborsClassifier
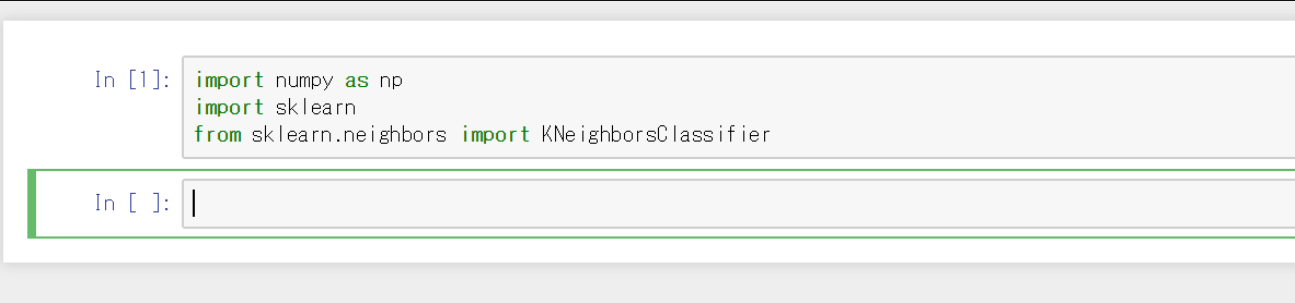
numpyは配列を作るライブラリで,KNeighborsClassifierは少し前に説明したK近傍法を使うためのライブラリです。
データと答えを読みこむ
それではせっかくなのでビールを購入するか予測してみましょう。
X = np.array([[1,1,0,0,1],[1,0,1,1,1],[0,1,1,0,1],[1,1,1,0,0],[1,1,0,1,1]]) #客が購入したものリスト(唐揚げ,枝豆,コーラ,おにぎり,チョコ)
y = np.array([[1],[0],[0],[1],[1]]) #客がビールを買ったかどうかリスト
予測精度を上げるためにチョコの欄を追加しました。特徴量が多い方がより複雑な予測ができます。順に唐揚げ,枝豆,コーラ,おにぎり,チョコとなっていて,一人目の人は唐揚げと枝豆とチョコを買いました。
scikit-learnではこのようなnumpy配列を使います。配列の中に配列を入れるだけです。この時,特徴量と答えの配列は順に対応していなければいけません。
[[1人目],[2人目],[3人目],...]
ここでは一人目の人([1,1,0,0,1])はyの[1]に対応しますね。

予測オブジェクトを作る
次に予測するアルゴリズムを変数に代入し,それを使って予測していきます。
knn = KNeighborsClassifier(n_neighbors=1) #knnにk近傍法アルゴリズムのオブジェクトを代入
knn.fit(X,y) #k近傍法アルゴリズムに特徴量Xと,その答えyをセット
knnは名前はなんでもOKです。knnは計算ができる機械だと思った方が分かりやすいかもしれません。その機会の.fitという機能に特徴量とその答えyを入れています。実はこれでもう学習は完了です。
予測してみる
ではまず既存の客のデータを入れて予測してみましょう。配列データを.predictメソッドに入れるだけで,その答えが配列で返ってきます。
knn.predict(X)
答えはこのようになりました。

この配列は先程与えたyと全く同じであることが分かります。つまり特徴量からビールを買った人を導くことができているのです!!
でも,これは学習に使われたデータなのだから答えがあっていて当然と言えば当然ですね。それでは上のような組み合わせで購入していない,新しい客ではどうなるのでしょうか
knn.predict([[1,1,0,0,0]]) #新規客 唐揚げと枝豆を買っているのでビールは買っていると予想される
答えはこうなりました

1が返ってきているので,ビールを購入すると予測出来ています。これで人間の勘をpythonに実装できましたね。ちょっと分かりやすくするために関数を作ってみました。
def predict_beer(X):
y = knn.predict(X)
if y[0] == 1:
print("この人はビールも買いそうです。")
else:
print("この人はビールは買わなそうです。")
これに対して,様々な組み合わせを入れてみた場合がこちらになります。

これからわかる通り,未知のデータに対して予測できていることが分かります。特に上2つは直感通りの予測をしてくれていますね。しかし3つ目のように間違った予測をすることもあります。これは学習に改善の余地がある=チューニングが足りないことを示しています。このチューニング方法などが載った聖書ともいえる本がありますので,後で紹介します。
ここまで,簡単な例を実装してきました。すべてのコードを合わせるとこうなります。
import numpy as np
import sklearn
from sklearn.neighbors import KNeighborsClassifier
X = np.array([[1,1,0,0,1],[1,0,1,1,1],[0,1,1,0,1],[1,1,1,0,0],[1,1,0,1,1]]) #客が購入したものリスト(唐揚げ,枝豆,コーラ,おにぎり,チョコ)
y = np.array([[1],[0],[0],[1],[1]]) #客がビールを買ったかどうかリスト
knn = KNeighborsClassifier(n_neighbors=1) #knnにk近傍法アルゴリズムのオブジェクトを代入
knn.fit(X,y) #k近傍法アルゴリズムに特徴量Xと,その答えyをセット
knn.predict(X)
knn.predict([[1,1,0,0,0]]) #新規客
def predict_beer(X):
y = knn.predict(X)
if y[0] == 1:
print("この人はビールも買いそうです。")
else:
print("この人はビールは買わなそうです。")
predict_beer([[1,1,0,0,0]])
思ったよりも数倍簡単に機械学習ができたのではないでしょうか。基本的に,knn = KNei…とした部分をランダムフォレストやニューラルネットワークに変えて,チューニングしていくといった流れをとります。
おすすめ書籍
私はpythonを全く触ったことがない状態から,まず退屈なことはpythonにやらせようという本である程度pythonを学びました。実用的で読みやすいです。
その次にこのscikit-learnの使い方を取り扱ったPythonではじめる機械学習という本で機械学習の基本を学びました。数式もほとんど使っておらず,実際の問題に特化した構成でかなり読みやすいです。(レビューも異常なほど評価が高い。それも納得できるレベル。)
ある程度pythonはできるという方は,2つ目の本から挑戦しても余裕だと思います。始めたい人は必ず買うべきです。今買いましょう。
また,この本はscikit-learnの開発者の一人が書いていて,本自体もjupyter notebook形式で無料公開されています。Github-introduction_to_ml_with_python
すべて英語なので,初心者の方は書籍を買うことをお勧めします。
いかがでしたでしょうか。意外と簡単に機械学習ができるんだということが伝われば幸いです!始めましょう,機械学習ライフ。


wak tech 先生はいつも具体的にわかりやすく書いていただき
感謝しています
python , 機械学習はよく聞く言葉なので調べたいと思っていた所でした
python の本は持っているのですがc++ 等と何か違うし AIが書いてあったりで不思議だと思っていましたが 理由がわかりました
ありがとうございます
これからの必需品というのは分かります
しかし 難しそうだ????