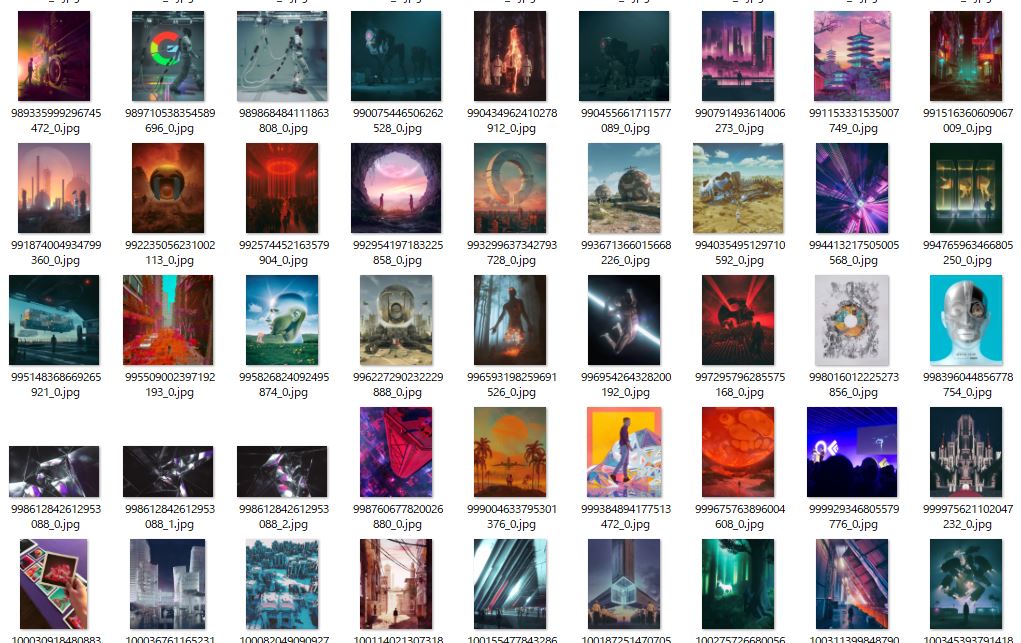
twitterAPIを使って好きなアカウントの画像を一度に取得したのでメモ。
beepleさんのように毎日素敵な画像を投稿している方の画像を一気に保存することができます。
[amazon_long]
目次
TwittterAPIの利用
TwitterAPIを利用できるようにする
Twitter APIに関してはこちらの記事が分かりやすいです。まずこれに従って
- Consumer Key(CK)
- Consmer Secret(CS)
- Access Token(AT)
- Access Token Secret(AS)
を取得します。
また,requests_oauthlibを使うので,コマンドプロンプト上で
pip install requests_oauthlib
を実行してライブラリをインストールしておきます。
TwitterにAPIキーでログインする
from requests_oauthlib import OAuth1Session
CK = '*****************************' # Consumer Key
CS = '********************************' # Consumer Secret
AT = '*************************************' # Access Token
AS = '****************************' # Accesss Token Secert
url_media = "https://upload.twitter.com/1.1/media/upload.json"
url_text = "https://api.twitter.com/1.1/statuses/update.json"
TL = "https://api.twitter.com/1.1/statuses/user_timeline.json"
# OAuth認証 セッションを開始
twitter = OAuth1Session(CK, CS, AT, AS)
これで,twitterというオブジェクトが生成されました。このtwitterオブジェクトに様々な操作をして画像などを取得していきます。
基本的な使い方
まずTLを取得しますが,誰の,どんな種類のツイートが欲しいかをparamsという辞書ファイル(json形式)に書き込みます。以下はbeepleさんのTL取得のためのparamsの例です。
params = {
"screen_name":beeple, //取得したい人のアカウント名(@を除く)
"count":200, //一度に取得したいツイート数(上限200)
"include_entities":True, //エンティティ(画像や動画など)を含むかどうかを指定
"exclude_replies":False, //その人が返信しているツイートを含むか
"include_rts":False //その人がリツイートしているツイートを含むか
}
次にタイムラインを取得します。
def getTL():
global req,timeline,content
req = twitter.get(TL,params=params)
timeline = json.loads(req.text)
TLは上記のurlのことで,これを使ってTLを取得しているようです。取得したTLオブジェクトであるreqはjson形式(辞書形式)なので,json.loads(req.text)でpythonで使える辞書形式に変換し,timelineに入れます。
試しにこのtimelineの中身を見てみましょう。
import json
from requests_oauthlib import OAuth1Session
CK = '*****************************' # Consumer Key
CS = '********************************' # Consumer Secret
AT = '*************************************' # Access Token
AS = '****************************' # Accesss Token Secert
url_media = "https://upload.twitter.com/1.1/media/upload.json"
url_text = "https://api.twitter.com/1.1/statuses/update.json"
TL = "https://api.twitter.com/1.1/statuses/user_timeline.json"
# OAuth認証 セッションを開始
twitter = OAuth1Session(CK, CS, AT, AS)
userID = input("userID:") //アカウント名を入力
GET_AT_ONCE = int(input("Get at once:")) //一度に取得したいツイート数を入力
params = {
"screen_name":userID,
"count":GET_AT_ONCE,
"include_entities":True,
"exclude_replies":False,
"include_rts":False
}
def getTL():
global req,timeline,content
req = twitter.get(TL,params=params)
timeline = json.loads(req.text)
getTL()
print(timeline)
入力
userID:beeple
Get at once:10
出力
{'created_at': 'Wed Jun 06 00:40:30 +0000 2018', 'id': 1004161071173824514, 'id_str': '1004161071173824514', 'text': 'BIOMETRIC WORKFORCE #everydayinmotion #cinema4d https://t.co/MXPpLP0mJf', 'truncated': False, 'entities': {'hashtags': [{'text': 'everydayinmotion', 'indices': [20, 37]}, {'text': 'cinema4d', 'indices': [39, 48]}], 'symbols': [], 'user_mentions': [], 'urls': [], 'media': [{'id': 1004160767963217920, 'id_str': '1004160767963217920', 'indices': [49, 72], 'media_url': 'http://pbs.twimg.com/ext_tw_video_thumb/1004160767963217920/pu/img/LpnblFedQ4_AKiuK.jpg', 'media_url_https': 'https://pbs.twimg.com/ext_tw_video_thumb/1004160767963217920/pu/img/LpnblFedQ4_AKiuK.jpg', 'url': 'https://t.co/MXPpLP0mJf', 'display_url': 'pic.twitter.com/MXPpLP0mJf', 'expanded_url': 'https://twitter.com/beeple/status/1004161071173824514/video/1', 'type': 'photo', 'sizes': {'thumb': {'w': 150, 'h': 150, 'resize': 'crop'}, 'small': {'w': 544, 'h': 680, 'resize': 'fit'}, 'medium': {'w': 800, 'h': 1000, 'resize': 'fit'}, 'large': {'w': 800, 'h': 1000, 'resize': 'fit'}}}]}, 'extended_entities': {'media': [{'id': 1004160767963217920, 'id_str': '1004160767963217920', 'indices': [49, 72], 'media_url': 'http://pbs.twimg.com/ext_tw_video_thumb/1004160767963217920/pu/img/LpnblFedQ4_AKiuK.jpg', 'media_url_https': 'https://pbs.t...
このように,
{'key1':value1,'key2':value2...'keyn':valuen}
という形式でツイート情報が記載されています。例えばcreated_atの値が欲しいときは,
print(timeline[0]['created_at'])
とすれば,
Wed Jun 06 00:40:30 +0000 2018
と出力されます。
[amazon]
画像を保存する
タイムラインから画像のURLを取得
画像のURLは
{'extended_entities':{'media':{'media_url':URL}}}
に保存されています。つまり,
image_url = timeline[0]["extended_entities"]["media"]["media_url"]
とすれば画像のURLを取得できます。
画像をフォルダに保存
urlで表された画像を保存するには,urllibを使います。
import urllib.request
urllib.request.urlretrieve(image_url,"image/image.png")
これで,timeline[0]に画像が含まれていた場合画像が保存できます。含まれていないとエラーになるので,最終的に以下のように分岐させて全ての画像を取得できるようにしました。
import json
import urllib.request
import os
from requests_oauthlib import OAuth1Session
CK = '*****************************' # Consumer Key
CS = '********************************' # Consumer Secret
AT = '*************************************' # Access Token
AS = '****************************' # Accesss Token Secert
url_media = "https://upload.twitter.com/1.1/media/upload.json"
url_text = "https://api.twitter.com/1.1/statuses/update.json"
TL = "https://api.twitter.com/1.1/statuses/user_timeline.json"
# OAuth認証 セッションを開始
twitter = OAuth1Session(CK, CS, AT, AS)
userID = input("userID:")
GET_COUNT = int(input("Get count:"))
GET_AT_ONCE = int(input("Get at once:"))
params = {
"screen_name":userID,
"count":GET_AT_ONCE,
"include_entities":True,
"exclude_replies":False,
"include_rts":False
}
def getTL():
global req,timeline,content
req = twitter.get(TL,params=params)
timeline = json.loads(req.text)
def saveContents():
for content in timeline: //timelineはGET_AT_ONCE個のツイートが含まれているので,contentで1つずつ選ぶ
if "extended_entities" in content: //画像や動画が入っている場合は"extended_entitiesがキーに含まれている
if "video_info" in content: //動画なら保存しない
print("video\n")
else: //動画ではない,つまり画像が含まれている場合
for count, photo in enumerate(content["extended_entities"]["media"]): //1ツイートに複数画像がある場合,"media":{imgURL1,imgURL2...}のようになっているため,1つずつ見ていく
title = foldername+"/"+content["id_str"]+"_"+str(count)+".jpg" //画像のタイトルを決める。画像にはid(id_str)が割り振られているため,それを利用してみた。
image_url = photo["media_url"] //画像のurlを取得
try: //まれに保存できない画像があるため,エラー処理
urllib.request.urlretrieve(image_url,title) //image_urlの画像をtitleという名前で保存
except:
print("error")
print("Image is saved successfully")
else:
print("No entities")
global num
num = content["id"] //最後のツイートのidを記録
foldername = "./images/"+userID //保存するフォルダの名前
if not os.path.exists(foldername): //保存フォルダが存在していない場合作成
os.makedirs(foldername)
for i in range(1,GET_COUNT): //GET_COUNTの分だけgetTL()を呼び出す
if(i==1):
params = params
else:
params.update({"max_id":num}) //呼び出すツイートの最大idを指定。こうしないと常に最新のGET_AT_ONCE件しか取得できない。
getTL() //TLをGET_AT_ONCE件取得
saveContents() //画像があれば保存
API制限のため,一度の呼び出しで取得できるツイート数は200件までです(2018/6時点)。そのため,GET_AT_ONCEに入力する値は200以下にします。
つまりこれをfor文の中に組み込み何度も200個ずつ読み込めば何千ツイートも取得できるわけです。しかし,この呼び出し回数も制限があり,180回/15分となっています。180回も呼べれば180×200ツイート取得できるわけですから,十分ですね。
この何回呼び出すのかは,GET_COUNTで指定しています。
[amazon_long]
まとめ
悪用するのはやめようね!



ありがとうございます!
とても参考になりました!
下記コードですが、「count」が未定義のためエラーになってしまいますね。
> for photo in content[“extended_entities”][“media”]:
> title = foldername+”/”+content[“id_str”]+”_”+str(count)+”.jpg”
上記コードの1行目を以下のように修正することで動作しました。
> for count, photo in enumerate(content[“extended_entities”][“media”]):
※countを定義しenumerateでインデックスを取得しています。
YUKIさん、記事を参考にしていただきありがとうございます。
役立ったようでよかったです!
ご指摘の通り、enumerateで画像のインデックスを取得してcountに入れないとだめでしたね…。大変助かりました。
記事は訂正済みです。