ベイズ最適化は非常に便利なツールですが、Pythonライブラリをそのまま使うには不便です。
普通研究者が過去のデータを保存しているのはExcelやcsvであって、直接入力するのには向きません。
このページでは、excelのデータを読み込み、次にするべき実験条件を提示してくれるシステムを作ります。
※Pythonを使ったベイズ最適化の基礎は実験屋のためのベイズ最適化入門をご覧ください。
目次
Excelファイルの読み込み・処理
Excelを読み込むため、以下のライブラリをインストールします。
pip install xlrd
pip install xlwt
次に、今までの条件が記述されているexcelファイルを準備します。
ここでは誰でもベイズ最適化を利用できるように、決まったexcelファイルのフォーマットを考えました。フォーマットは以下の通りです。

一番上がタイトル行。ここには各種変数(温度や圧力など)と出力(ピークの比や物性値)の名前を入れます。
2-5行目が各変数の設定。
一行目は入力変数(i)か、出力変数(o)か、それともその値は無視するか(r)を入力します。
二行目はその値が連続値(c)か0/1のブール(d)かを指定します。
三行目は最小値、四行目は最大値を指定します。ブールの場合は0,1と書きましょう。
また、ここで注意したいのが出力の数です。残念ながらマルチターゲットには対応していないため、oと入力する変数は一つのみにしましょう。
複数条件を最適化したい場合は、それぞれ重みをつけて、1つの列にし、それを出力として設定すると良いです。
今回は醤油、みりん、砂糖、酒の4変数で、出力が味です。ベイズ最適化の初期設定では目的変数の値が小さいものを探すため、味0を最高値とします。味は以下の式で決まると仮定してみましょう。
味 = (醤油-0.5)^2 + (みりん-0.2)^2 + (砂糖-0.5)^2 + (酒-1)^2/5
つまり極小値は0で、醤油=0.5,みりん=0.2,砂糖=0.5,酒=1 です。これが見つかるか試していきます。
Excelファイルを読み込む
テンプレートファイルはこちらで配布していますのでダウンロードしてください。
テンプレートファイルの名前がBO_test.xlsxだと仮定します。
以下の手順でexcelファイルをpythonに読み込みます。
import xlrd
#excelファイルに読み込み
wb = xlrd.open_workbook("./BO_test.xlsx")
print(wb.sheet_names())
sheet = wb.sheet_by_name('Sheet1')
columns = [sheet.col_values(i) for i in range(sheet.ncols)]
同一フォルダ内にファイルを用意するのが面倒な場合は、代わりに以下のようにwbを読み込みましょう。
エクスプローラが開き、直感的にファイルを選択できます。
import os, tkinter, tkinter.filedialog, tkinter.messagebox
# ファイル選択ダイアログの表示
root = tkinter.Tk()
root.withdraw()
fTyp = [("","*")]
tkinter.messagebox.showinfo('input file selection','select a xlsx file')
file = tkinter.filedialog.askopenfilename(filetypes = fTyp)
wb = xlrd.open_workbook(file)
ここでは、”Sheet1″という名前のシートの全列の情報をcolumnsに入れました。columnsを見てみましょう。
print(columns)

各列(縦方向)の情報がそれぞれリストになっているのが分かります。各列にアクセスするには、例えば5番目の列の場合はcolumns[5]とすればOKです。
入力値を振り分ける
先程のリストには要らないもの(r)と入力(i)、出力(o)が詰まっています。入力と出力だけ取り出してみましょう。
#入力と出力の値を振り分け
inputs = []
inputs_numtype = []
inputs_domain = []
inputs_name = []
outputs = []
outputs_name = []
for i, column in enumerate(columns):
if column[1] == "i":
inputs_name.append(column[0])
inputs.append(column[5:])
inputs_numtype.append(column[2])
inputs_domain.append([float(column[3]),float(column[4])])
if column[1] == "o":
outputs_name.append(column[0])
outputs.append(column[5:])
2行目にiと書かれている場合は入力なので、5行目以降の情報をinputsリストに、値のタイプをinputs_numtypeに入れています。
同様にoと書かれている場合は、名前をouputs_nameに、値をoutputsに格納します。
ベイズ最適化
いよいよベイズ最適化をしていきます。以下のコードを実行してGPyOptを読み込みましょう。
#ベイズ最適化のセッティング
import GPyOpt
import numpy as np
入力値の変換
GPyOptにデータを読み込ませるには、少し工夫が必要です。以下のコードを実行します。
#予備実験のデータ
initial_x = np.array(inputs).T
initial_y = np.array(outputs[0])
initial_y = initial_y.reshape((-1,1))
print(initial_x)

このように、2次元のリストにする必要があります。excelから読み取ったデータは列ごとになっているため、numpy配列に対して転置操作(.T)を行い、上記のようなリストへと加工しました。
yに関しても同様で、デフォルトでは1次元のリストになっているため、reshapeで幅1の2次元行列にしました。
関数の設定
最適化する関数を設定します。ここでは次に試した方がいい実験条件を提示し、その結果を入力させる関数にしました。
for文の中で、各最適化する変数の名前と、そのパラメータを出力しています。
def f(x):
print("next x")
for n,value in zip(inputs_name,x[0]):
print(n + ":" + str(value))
score = float(input("Input y : "))
return score
条件の登録
ベイズ最適化の条件を設定しておきましょう。Excelの上4行に記入した、各変数の種類や上限をboundsにセットしていきます。
bounds = []
for i,input_name in enumerate(inputs_name):
bound = {}
bound["name"] = input_name
if inputs_numtype[i] == "c":
bound["type"] = "continuous"
elif inputs_numtype[i] == "d":
bound["type"] = "discrete"
bound["domain"] = tuple(inputs_domain[i])
bounds.append(bound)
ベイズ最適化の開始
上記で登録したboundsと過去データを以下のようにセットし、ベイズ最適化オブジェクト(myBopt)を生成します。
myBopt = GPyOpt.methods.BayesianOptimization(f=f,
domain=bounds,
X = initial_x,
Y = initial_y,
normalize_Y=False,
model_type = "GP",
acquisition_type='LCB',
)
ベイズ最適化に最大試行回数を入れ、走らせてみましょう。
実験に時間がかかり、Pythonをつけたままにしておけない場合はmax_iter=1に設定しておくとよいです。
for i in range(30):#このfor文は人間が回す
myBopt.run_optimization(max_iter=1)
実験をする
提示された条件で実験をしてみましょう。その実験の結果をexcelに追記して終了です。
満足のいく実験結果が得られるまで、これまでの手順(excelの読み込みからrun_optimization迄)を繰り返します。

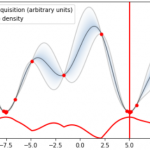
最適化回数始めの場合は上記のような感じに。毎回分散が大きい実験条件を指定し、最適な値を見つけようとしてくれています。
30ステップ周辺はこちら

もうほぼ最適な値(0.5,0.2,0.5,1)にたどり着いています。
この結論に20ステップ目でたどり着いているため、変数が4つあるにもかかわらず非常に少ないコストで条件を最適化できたことになります。
最適化された値の取得
最適化された値は以下のように取得可能です。
print(myBopt.x_opt)#最適な条件
print(myBopt.fx_opt)#最適な条件での結果



大変参考になりました。
質問があります。
制約条件として、「醤油とみりんと砂糖の合計が1になる」ようにするにはどうすればいいのでしょうか?(1が100%というイメージです。)
以上、宜しくお願い致します。
参考になったようでなによりです。
GpyOptには制約条件をつけられる「Constraint」オプションがあります。
https://cloud6.net/so/python/3468339
私も制約条件入れたことが無いのですが、見る限り簡単にできそうです。
ありがとうございました😃
わくてくさん
また、ご教授頂きたいことがあります。
提示された条件をcsvファイルに自動で保存していくようにするにはどうすればいいのでしょうか?
以上、宜しくお願い致します。
こちらのブログ(https://hk29.hatenablog.jp/entry/2020/11/22/235805)に、ベイズ最適化した結果をcsvに出力する方法が記載されていました。
def f(x):の中身で出てくるxには次の提示条件が入っているため、def f(x)の中でこのlistをcsvに出力してあげれば良さそうです。
csvの出力はpandasが便利です。pandasのto_csvメソッドには追記モードがあるため、一度csvを作っておけばどんどん実験した条件が自動で追加されていくようにできると思います。to_csvの使い方→https://note.nkmk.me/python-pandas-to-csv/
わくてくさん
出来ました。ありがとうございました。
初めまして。Pythonでベイズ最適化を行い材料開発を効率化しようと試みています。
こちらの記事が大変参考になりました。ありがとうございました。
ひとつ質問なのですが、LCBのacquisition_weight(デフォルトは2?)はどのようなコードで入力、変化させれば良いのでしょうか。
よろしくお願いします。
参考になったようで嬉しいです。
acquisition_weightをパラメータとして設定している解説記事がありましたのでご参考ください。
https://qiita.com/oki_kosuke/items/fe29c297fa68ed1b3cba
参考記事、ありがとうございます。よく読んでみます。